Components of modern web applications
When it comes to software architecture, there’s never a single solution that’s always applicable. The answer to “what technologies should I use?” is always “it depends.” It depends on what problem you’re trying to solve, the size of your team, how mission-critical it is and how reliable it needs to be, what scale of usage you’re looking at, and plenty of other factors. But there are some general principles to apply and some very common situations where we can get more into specifics if we narrow our focus.
At JetBridge we’ve built dozens of applications, for clients and sometimes launched our own products as well. We’ve done everything from synthetic biology visualization to ad retargeting, from emergency radio IoT monitors to advanced telephony. In nearly every case though, we’ve been building database-backed web applications with some of web frontend. Not every software project is this, but nearly everything we’ve encountered has been something pretty close. So let’s talk about our preferred architectural components, drawing on our extensive experience and hard-won lessons from deploying profit-making applications in the real world.
In short: vibe-friendly, cloud-native serverless applications with great observability and data integrity.
Vibe-friendly
Creating software in 2026 is a fundamentally different paradigm than even a year ago. When Claude Opus 4.5 came out at the end of 2025, there was a real industry–wide vibe shift. Some of the most fastidious, conscientious engineers I know are not really writing code line by line anymore. They have multiple agents going and are spending their time refining their skills and commands, spending more time on testing and reviewing their greatly increased output, and busting out entire applications in their spare time with barely lifting a finger. It can even be addictive, prompting Claude Code with your fantasies about extensive test coverage or wacky UIs or great migrations from one framework to another. Maybe part of the addiction is the slot machine effect; getting a random reward when it actually does exactly what you wanted, which is becoming more frequent compared to even a few months ago.
What does this have to do with your tech stack? Popular technologies that are well-documented, mature, and ideally somewhat static, have an even greater attractiveness than before. It’s true that not everyone chooses their technologies purely by popularity, but I believe for most pragmatic-minded engineers it is an important factor. How easy is it to hire someone who already understands the technology? How many edge cases has it hit and solved for? How good are the docs? Is there a community of people who can answer your questions or respond to your PRs?
These have always been important questions when choosing a technology, but it hasn’t stopped many companies from adopting slightly less popular technologies for various practical or ideological reasons. Vue instead of React, Scala instead of Java, hell even a few places run some FreeBSD. If we only went with the most widespread technologies we’d all be writing WordPress plugins.
LLMs theoretically have most software documentation in their training sets, but they sure hallucinate a lot more for technologies that don’t have oodles of example code and stable documentation. Agents are not bad at combing GitHub issues or StackOverflow posts when you run into issues. Also, when libraries have a major change in how they between versions, work, LLMs often will write code in the old style, for example writing SQLAlchemy 1-style code even though they have a new style in version 2. Regarding making LLMs RTFM, you can always feed in migration guides which can help a lot in some cases, but I recommend hooking up a MCP tool like Context7 which knows how to fetch docs for all sorts of languages.
Another thing to consider is strict well-typed languages or configurations. I’m talking about TypeScript as the default case for your backend and frontend with all strict mode options and authoritarian style eslint rulesets. It’s great for strong typing, the ecosystem has really matured in a big way the last few years, has terrific tooling, is getting way faster to compile, lets your agents keep more coherent context about your entire application, and you probably need to use it for your frontend anyway. Make your agent crank out a ton of strict CI checks and linting and formatting.
For lower-level projects, Rust is strongly worth considering because the compiler is absolutely amazing at enforcing safe practices and gives you so much useful hints at compile-time. It gives the kind of feedback that really forces agents into writing robust and well-structured and safe code. It may not be the most readable code however unless you’re already pretty handy with Rust syntax, because it comes close to Perl in its range of syntactic punctuation.
Language
If your application has a web frontend then you pretty much have no choice except TypeScript for it. If part of your application is in TypeScript, it usually makes sense to default the backend to TypeScript as well to share one set of tooling, CI, types, and orchestrate it all in a monorepo. There can be great reasons to have your backend in a different language, probably the most common reason being if your application is heavy on data science, then Python is likely the only reasonable option there.
The JS-derivative community including Node, Deno, TypeScript, Bun, etc has really matured in recent years. It was something of a wild west five or ten years ago but the quality of tooling and libraries has evolved a great deal and become mature and stable enough to build software on top of and enjoy it too. Plenty of the important build and linting tools have cores written in Rust or Go now for improving development speed, such as esbuild, TypeScript, biome, vite, and turbopack.
Cloud-native
We’ve been writing about cloud-native application architecture for a decade. The brief version is: you shouldn’t be focusing on the operational details of solved problems.
Your time and resources should be focused on whatever you’re doing that is unique and delivering value to someone. Applying patches to a webserver, configuring iptables, setting up your own monitoring system from scratch, customizing OSes, and coming up with server naming schemes are probably not tasks which differentiate your organization from others. AWS can do a better job of setting up highly available systems and managing storage and transit than you can. Take advantage of their vast offering of managed services and focus on your product.
What cloud provider to use depends on what your org is already using generally, but if you’re starting out, I recommend AWS because it’s been around the longest and is still the clear leader in market share.
Serverless
Serverless means different things to different people but generally it’s a philosophy of focusing on differentiated logic and features that deliver value for you and your customers. It doesn’t mean there are no servers, of course your code is running somewhere. It means you probably shouldn’t be concerning yourself with where it’s running or managing pets. You shouldn’t know IP addresses or hostnames generally speaking. I like Lambda and Fargate because they epitomize the concept of “here’s my code just run it somewhere I don’t care where.” Kubernetes is a great choice if you have some really custom or specialized uncommon setup, of if you happen to be Google, but if you’re running a database-backed web application, you need Kubernetes like an English major college student needs a supercomputer cluster.
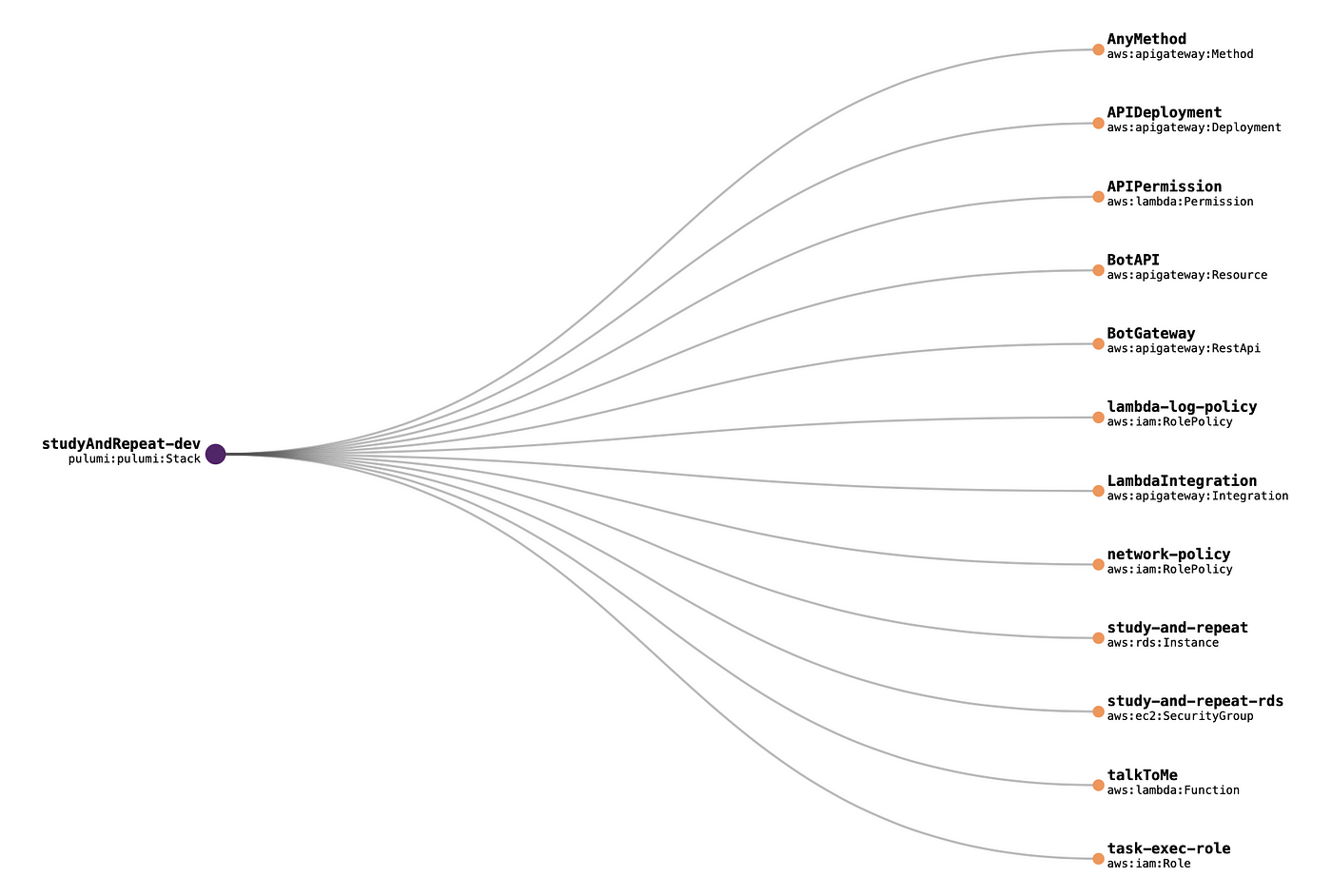
One of the biggest challenges withe cloud-native serverless development is having a local development environment. If you’re writing mostly lambda functions, you want to do your testing in an environment where all of your cloud resources are present but with rapid iteration. Our go-to tool for this for many years has been a fantastic open-source project called Serverless Stack.
Serverless Stack
It’s not a huge framework of its own or anything, it’s some really focused useful tools on top of existing technology that provide some killer features. In a nutshell it’s for defining infrastructure-as-code with Pulumi, but you get tight integration of your cloud resources (e.g. queues, databases, S3 buckets, functions) with your runtime code, super fast and easy deployments, integrated monitoring, and live local lambda development. It’s what AWS SAM should be but isn’t. We’ve made so many apps with this tool and love it.
When you set up your new project, include “Use SST v3” in your prompt.
Observability
Hopefully I don’t need to sell anyone on the importance of observability, also known as knowing when your stuff breaks, but it’s something we’ve taken particular pride in when building applications. I love to create custom CloudWatch dashboards connected to the important cloud resources like Aurora serverless capacity, or API Gateway 5xx errors, or DLQ stats, but also custom application-level metrics.
If you use Serverless Stack, it has a super handy console where any errors your functions throw show up, and you can have it alert you by email or slack notification. It’s super super useful.
I highly recommend the AWS Lambda Powertools libraries. They have fantastic features for building middleware stacks, emitting custom metrics, distributed tracing, structured logging, type definitions for AWS events, idempotency helpers, and new features coming out every month it seems.
Another great MCP tool is the Sentry MCP tool, and AWS has a whole suite of them but connecting to CloudWatch is super handy. These can supercharge your agent when debugging issues. I also recommend the AWS Cost Explorer MCP tool for having agents optimize your cloud spend.
Putting It Together
If you’re looking to build a new database-backed web application and want to use modern but dependable and mature technologies, here’s a list of our favorite packages. Paste this into your agent to start a new project:
- Frontend: Next.js, Tailwind
- Auth: Better Auth (email/password) with organizations
- API: tRPC
- DB: Postgres + Drizzle ORM
- Infra: Serverless Stack (with NextjsSite)
- Tests: Vitest
- Linting: Biome
Our choices are based partly on what’s worked great for us over many projects and partly on popularity and ubiquity. They combine nicely to enable rapid, type-safe development (Next.js, tRPC, Vitest) and an unparalleled local development experience for cloud-native applications (SST).
Prisma is a very strong ORM option as well but it does tend to have considerable overhead and constraints, and much of the time a simpler query builder like Drizzle will do just fine.
Next.js is really just the industry standard now, and extremely mature and covers any sort of use case you’re going to want to handle in your web application. Open-next is used to deploy your application natively to AWS and is a tool JetBridge has contributed to.
This is our favorite setup in 2026, both for the type-safe end-to-end structure as well as the combination of maturity and modernity these tools have. It’s not the right setup for every project but it’s our recommended default starting point. Have some fun with it.