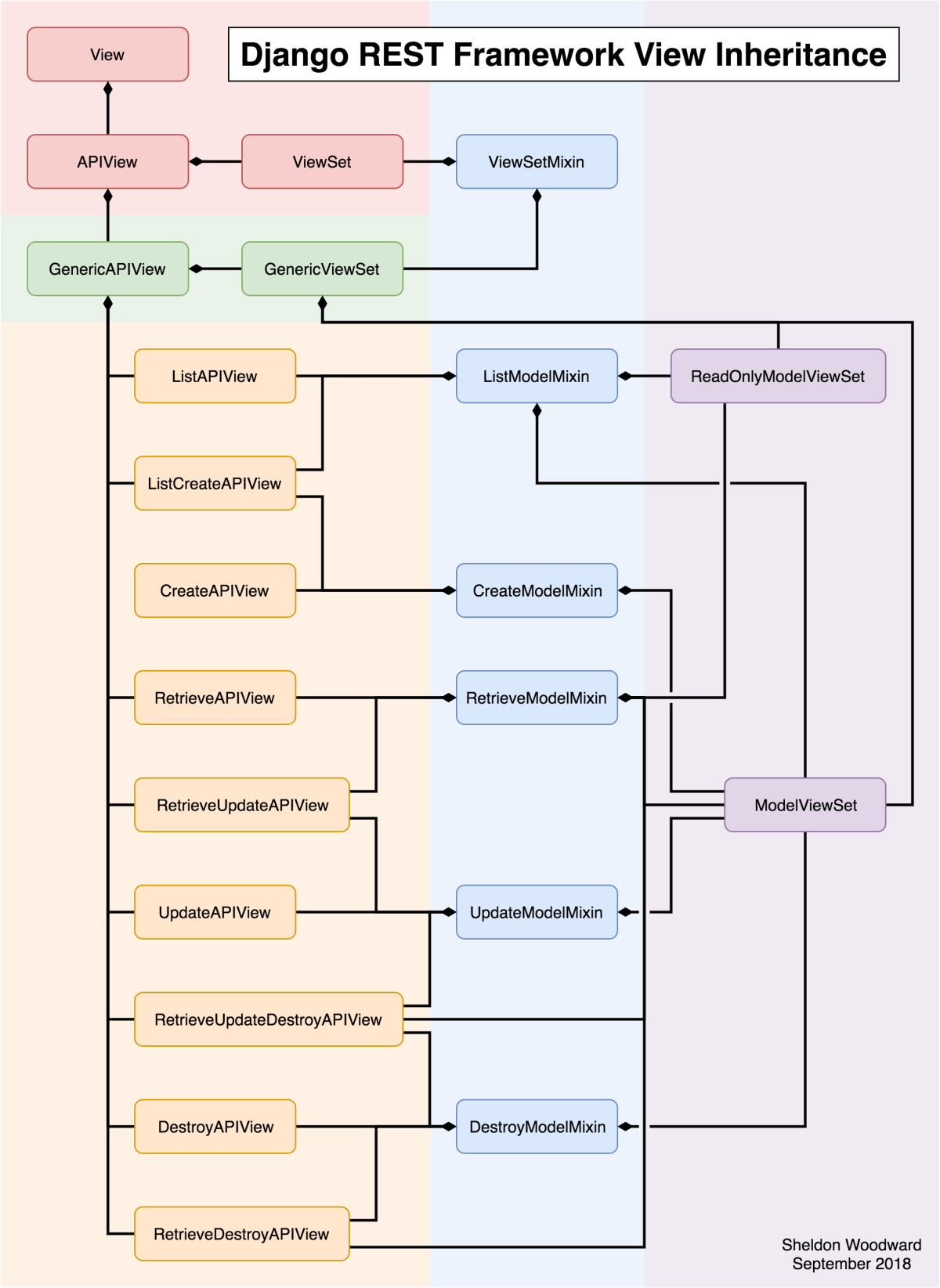
The defi revolution is in full swing if you know where to look. Serious efforts to build out and improve the underlying infrastructure for smart contracts as well as applications, art, and financial systems are popping up almost every week it seems. They use their own native tokens to power their networks, games, communities, transactions, NFTs and things that haven’t been thought up yet. As more decentralizated autonomous organizations (DAOs) track their assets, voting rights, and ownership stakes on-chain the market capitalization of tokens will only increase.

There are as many potential uses for crypto tokens as there are for fiat money, except tokens in a sense “belong” to these projects and shared endeavours. If enough hype is built up, masses of people may speculate to the tune of hundreds of billions of dollars that the value of the tokens will increase. While many may consider their token purchases to be long-term investments in reputable projects with real utility, sometimes coming with rights or dividend payments, I believe a vast majority of people are looking to strike it rich quick. And some certainly have. The idea that you can get in early on the right coin and buy at a low price, and then sell it to someone not as savvy later on for way more money is a tempting one. Who doesn’t want to make money without doing any real work? I sure do.
Quickstart
If you want to skip all of the explanations and look at code you can run, you can download the JupyerLab Notebook that contains all of the code for creating and optimizing a strategy.
Now for some background.
Trading and Volatility
These tokens trade on hundreds of exchanges around the world from publicly-held and highly regulated Coinbase to fly-by-night shops registered in places like the Seychelles and Cayman. Traders buy and sell the tokens themselves as well as futures and leveraged tokens to bet on price movement up and down, lending tokens for other speculators to make leveraged bets, and sometimes actively coordinating pump and dump campaigns on disreputable discords. Prices swing wildly for everything from the most established and institutionally supported Bitcoin to my own MishCoin. This volatility is an opportunity to make money.
With enough patience anyone can try to grab some of these many billions of dollars flowing through the system by buying low and selling higher. You can do it on the timeframe of seconds or years, depending on your style. While many of the more mainstream coins have a definite upwards trend, all of them vacillate in price on some time scale. If you want to try your hand at this game what you need to do is define your strategy: decide what price movement conditions should trigger a buy or a sell.

Since it’s impossible to predict exactly how any coin will move in price in the future this is of course based on luck. It’s gambling. But you do have full control over your strategy and some people do quite well for themselves, making gobs of money betting on some of the stupidest things you can imagine. Some may spend months researching companies behind a new platform, digging into the qualifications of everyone on the team, the problems they’re trying to solve, the expected return, the competitive landscape, technical pitfalls and the track record of the founders. Others invest their life savings into an altcoin based on chatting to a pilled memelord at a party.
Automating Trading
Anyone can open an account at an exchange and start clicking Buy and Sell. If you have the time to watch the market carefully and look for opportunities this can potentially make some money, but it can demand a great deal of attention. And you have to sleep sometime. Of course we can write a program to perform this simple task for us, as long as we define the necessary parameters.
I decided to build myself a crypto trading bot using python and share what I learned. It was not so much a project for making real money (right now I’m up about $4 if I consider my time worth nothing) as a learning experience to tech myself more about automated trading and scientific python libraries and tools. Let’s get into it.
To create a bot to trade crypto for yourself you need to do the following steps:
- Get an API key for a crypto exchange you want to trade on
- Define, in code, the trading strategy you wish to use and its parameters
- Test your strategy on historical data to see if it would have hypothetically made money had your bot been actively trading during that time (called “backtesting”)
- Set your bot loose with some real money to trade
Let’s look at how to implement these steps.
Interfacing With an Exchange
To connect your bot to an exchange to read crypto prices, both historical and real-time, you will need an API key for the exchange you’ve selected.

Fortunately you don’t need to use a specialized library for your exchange because there is a terrific project called CCXT (Crypto Currency eXchange Trading library) which provides an abstraction layer to most exchanges (111 at the the time of this writing) in multiple programming languages.
It means our bot can use a standard interface to buy and sell and fetch the price ticker data (this is called “OHLCV” in the jargon – open/high/low/close/volume data) in an exchange-agnostic way.
Now, the even better news it that we don’t really even have to use CCXT directly and can use a further abstraction layer to perform most of the grunt work of trading for us. There are a few such trading frameworks out there, I chose to build my bot using one called PyJuque but feel free to try others and let me know if you like them. What this framework does for you is provide the nuts and bolts of keeping track of open orders, buying and selling when certain triggers are met. It also provides backtesting and test-mode features so you can test out your strategy without using real money. You still need to connect to your exchange though in order to fetch the OHLCV data.
Configuring the Trading Engine
PyJuque contains a number of configuration parameters:
- Exchange API key
- Symbols to trade (e.g.
BTC/USD,ETH/BTC, etc) - Timescale (I use 15 seconds with my exchange)
- How much money to start with (in terms of the quote, so if you’re trading
BTC/USDthen this value will be inUSD) - What fraction of the starting balance to commit in each trade
- How far below the current price to place a buy order when a “buy” signal is triggered by your strategy
- How much you want the price to go up before selling (aka “take profit” aka “when to sell”)
- When to sell your position if the price drops (“stop loss”)
- What strategy to use to determine when buy signals get triggered
Selecting a Strategy
Here we also have good news for the lazy programmers such as myself: there is a venerable library called ta-lib that contains implementations of 200 different technical analysis routines. It’s a C library so you will need to install it (macOS: brew install ta-lib). There is a python wrapper called pandas-ta.
All you have to do is pick a strategy that you wish to use and input parameters for it. For my simple strategy I used the classic “bollinger bands” in conjunction with a relative strength index (RSI). You can pick and choose your strategies or implement your own as you see fit, but ta-lib gives us a very easy starting point. A future project could be to automate trying all 200 strategies available in ta-lib to see which work best.
Tuning Strategy Parameters
The final step before letting your bot loose is to configure the bot and strategy parameters. For the bollinger bands/RSI strategy we need to provide at least the slow and fast moving average windows. For the general bot parameters noted above we need to decide the optimal buy signal distance, stop loss price, and take profit percentage. What numbers do you plug in? What work best for the coin you want to trade?
Again we can make our computer do all the work of figuring this out for us with the aid of an optimizer. An optimizer lets us find the optimum inputs for a given fitness function, testing different inputs in multiple dimensions in an intelligent fashion. For this we can use scikit-optimize.
To use the optimizer we need to provide two things:
- The domain of the inputs, which will be reasonable ranges of values for the aforementioned parameters.
- A function which returns a “loss” value between 0 and 1. The lower the value the more optimal the solution.
from skopt.space import Real, Integer
from skopt.utils import use_named_args
# here we define the input ranges for our strategy
fast_ma_len = Integer(name='fast_ma_len', low=1.0, high=12.0)
slow_ma_len = Integer(name='slow_ma_len', low=12.0, high=40.0)
# number between 0 and 100 - 1% means that when we get a buy signal,
# we place buy order 1% below current price. if 0, we place a market
# order immediately upon receiving signal
signal_distance = Real(name='signal_distance', low=0.0, high=1.5)
# take profit value between 0 and infinity, 3% means we place our sell
# orders 3% above the prices that our buy orders filled at
take_profit = Real(name='take_profit', low=0.01, high=0.9)
# if our value dips by this much then sell so we don't lose everything
stop_loss_value = Real(name='stop_loss_value', low=0.01, high=4.0)
dimensions = [fast_ma_len, slow_ma_len, signal_distance, take_profit, stop_loss_value]
def calc_strat_loss(backtest_res) -> float:
"""Given backtest results, calculate loss.
Loss is a measure of how badly we're doing.
"""
score = 0
for symbol, symbol_res in backtest_res.items():
symbol_bt_res = symbol_res['results']
profit_realised = symbol_bt_res['profit_realised']
profit_after_fees = symbol_bt_res['profit_after_fees']
winrate = symbol_bt_res['winrate']
if profit_after_fees <= 0:
# failed to make any money.
# bad.
return 1
# how well we're doing (positive)
# money made * how many of our trades made money
score += profit_after_fees * winrate
if score <= 0:
# not doing so good
return 1
# return loss; lower number is better
return math.pow(0.99, score) # clamp 1-0
@use_named_args(dimensions=dimensions)
def objective(**params):
"""This is our fitness function.
It takes a set of parameters and returns the "loss" - an objective single scalar to minimize.
"""
# take optimizer input and construct bot with config - see notebook
bot_config = params_to_bot_config(params)
backtest_res = backtest(bot_config)
return calc_strat_loss(backtest_res)
Once you have your inputs and objective function you can run the optimizer in a number of ways. The more iterations it runs for, the better an answer you will get. Unfortunately in my limited experiments it appears to take longer to decide on what inputs to pick next with each iteration, so there may be something wrong with my implementation or diminishing returns with the optimizer.

The package contains various strategies for selecting points to test, depending on how expensive your function should be. If the optimizer is doing a good job exploring the input space you should hopefully see loss trending downwards over time. This represents more profitable strategies being found as time goes on.

After you’ve run the optimizer for some time you can visualize the search space. A very useful visualization is to take a pair of parameters to see in two dimensions the best values, looking for ranges of values which are worth exploring more or obviously devoid of profitable inputs. You can use this information to adjust the ranges on the input domains.

You can also visualize all combinations of pairs of inputs and their resulting loss at different points:

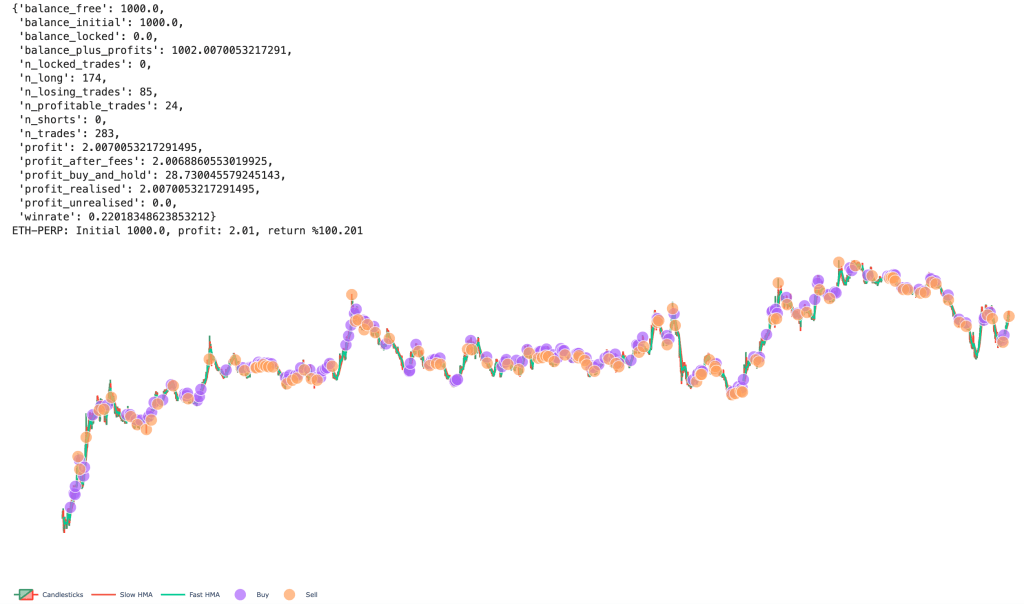
slow_ma_len and fast_ma_len have distinct steps in their inputs vs. the more “messy” real number inputs.After running the optimizer for a few hundred or thousand iterations it spits out the best inputs. You can then visualize the buying and selling the bot performed during backtesting. This is a good time to sanity-check the strategy and see if it appears to be buying low and selling high.

Run the Bot
Armed with the parameters the optimizer gave us we can now run our bot. You can see a full script example here. Set SIMULATION = False to begin trading real coinz.
All of the code to run a functioning bot and a JupyterLab Notebook to perform backtesting and optimization can be found in my GitHub repo.
I want to emphasize that this system does not comprise any meaningfully intelligent way to automatically trade crypto. It’s basically my attempt at a trader “hello world” type of application. A good first step but nothing more than the absolute basic minimum. There is vast room for improvement, things like creating one model for volatility data and another for price spikes, trying to overcome overfitting, hyperparameter optimization, and lots more. Also be aware you will need a service such as CoinTracker to keep track of your trades so you can report them on your taxes.