Python and related tooling continues to progress and evolve. I’d like to share some of the tools and practices we’re using at JetBridge to develop python web applications.
This is by no means an exhaustive account or a definite list of all best practices, and I hope readers will share what’s working well for them so I can learn and incorporate that knowledge. I don’t know about everything out there but I can at least present a survey of what we’ve been using on multiple projects with success.
Python
Let’s start with… python. As of January 1st, 2020 python 2 support was officially discontinued. If you are still maintaining any python 2 code you are using the language equivalent of Windows XP. Not only is python 2 no longer receiving security updates but now all python module authors will feel comfortable dropping any support for python 2 in any future versions of their modules, which means your dependencies are unlikely to receive security updates as well. Using python 2 is now a legitimate security risk.
Python 3.8 is out. What’s new in it?
The “walrus operator” := allows you to initialize a variable as part of any expression and save a line or two of code. The battle in PEP 572 over getting this operator included in the language was so unpleasant that it caused Guido van Rossum to ragequit his Benevolent Dictator For Life of Python role.
__pycache__ directories are now managed out-of-tree so they stop polluting your deployments and source control.
New additions to python’s type system – TypedDict lets you define the shape of a dictionary type, Literal lets you easily construct literal value constraints such as for enumerated value options, and at long last we have built-in support for structural subtyping, also known as Protocols.
F-string debug syntax – now instead of writing:
print(f"blorp={blorp}")
You can write:
print(f"{blorp=}")
Which is terrific news for those of us who will continue using print statements to debug until the day we die.
Python 3.9 is expected out in October 2020.
Linting and Formatting
Keeping your code neat and formatted can really help with readability and enforcing a consistent style. The tooling can also help catch potential bugs or mistakes. Here’s what we’re using:
Flake8 – Classic Linting Tool
Run as a pre-commit hook or in your CI flow. We suggest installing and enabling the plugins:
tox.ini configuration:
[flake8]
ignore = E305,E402,E501,I101,I100,I201
max-line-length = 160
exclude = .git,__pycache__,build,dist,.serverless,node_modules,migrations,.venv,.bento
enable-extensions = pep8-naming,flake8-debugger,flake8-docstringsMypy – Type Checking
Mypy performs the useful function of type-checking, to the extent one can in python. It does on some occasions catch useful errors for you and is improving as time goes on. Still, the usefulness of python’s bolted-on type system afterthought is limited compared to say, any other typed language.
If you are adding it to an existing project with many dependencies you may need to add ignore_missing_imports = True to your mypy.ini configuration file until you can resolve all of the warnings you’re going to get.
Bento – Static Analysis
Bento is a very new tool that attempts to be sort of a meta-linter, combining a number of different checker tools into one, most notably Bandit, a “Security oriented static analyser for python code.” It’s designed to integrate into git hooks and CI workflows relatively easily. It’s still quite new and not super mature yet but this is definitely a tool to keep your eye on. The analysis engines are open source and provided for free, though the company behind it is working to offer paid features for larger teams.
Black – Formatting
Black is a brutal and fantastic code formatter, much like prettier for python. It can be run as a pre-commit hook to make sure your code is formatted correctly, or you can have your editor run it automatically on save (my preference). It is technically possible to modify the formatting rules but there is no reason you should ever do that. Just enable it, always run it on every changed file, and never worry about 97% of code formatting issues ever again.
Workflow Integration
People are of differing opinions on whether you should add these tools into your editor, git hooks, or CI pipeline. Personally I have all of these tools hooked into my editor (mostly spacemacs but giving PyCharm a try) and love having my code formatted upon saving and seeing type errors inline in my code. This is definitely the best way to develop but it doesn’t enforce any standards in your team. Maybe you can always expect the people working on your project to have their editors configured correctly but this is mostly unrealistic for most teams.
You can add it as a pre-commit (or pre-push) git hook, which ensures everything is run before it goes to CI. The downside is this can add extra setup steps for the project or greatly increased execution time for common git commands.
Another option is to run all of your checks in CI and let developers be responsible for committing code that is correct or suffer failed tests. I have CircleCI configured to install dependencies and then run the checks as separate jobs in parallel.
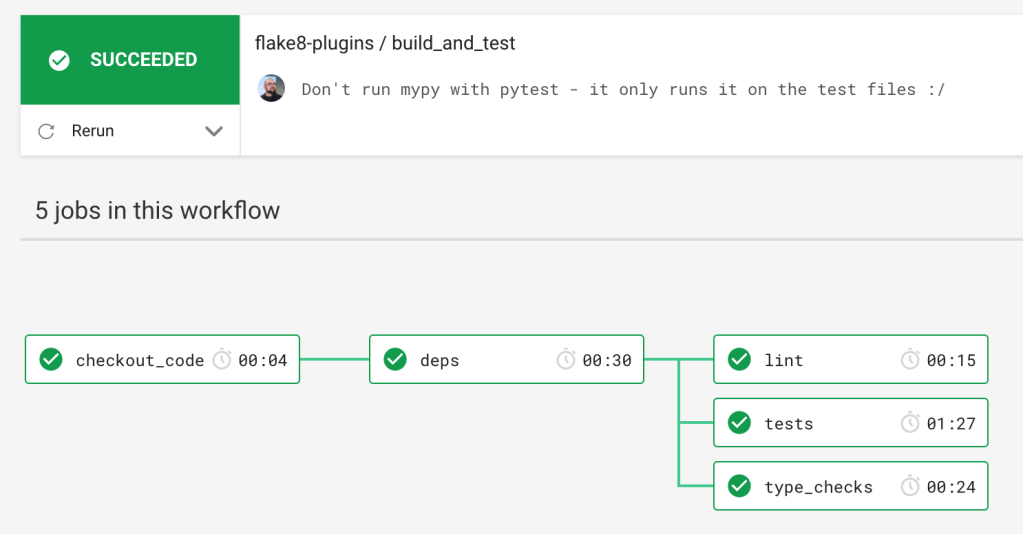
And these options are not mutually exclusive. You can totally do all three together.
Testing
Switching away from unittest.TestCase and lots of custom helper functions to create objects in favor of pytest fixtures and factoryboy made testing vastly more pleasant, especially when writing tests that talk to the database.
Our setup for writing tests that interact with Flask and SQLAlchemy is to set up fixtures with factoryboy which helps you declaratively write fixture factories for all your database models and pytest-factoryboy which lets you register your factories as pytest fixtures. The plugin pytest-postgresql allows easy creation of a PostgreSQL database for running tests and pytest-flask-sqlalchemy patches in a mocked database session (or sessionmaker or engine if you need them) during tests that ensures each test runs in a subtransaction. Subtransactions (aka SAVEPOINT) allow you to run each test isolated in its own transaction and all changes are rolled back at the end of the test. This allows each test to be invisible to any other test or transaction and also to have all database changes cleaned up automatically. This is the most efficient way to run database tests with a high degree of reproducibility to how your application will be running for real.
There are a lot of pieces here but they fit together beautifully in the end. Your test setup may look something like this:
myapp/db/fixture.py – where we like to define database factories. These can be used for populating development environments and tests with sample DB rows.
from faker import Factory as FakerFactory
import factory
from jetkit.db import Session # see https://github.com/jetbridge/jetkit-flask/blob/e3fc3448933ffbfb573cc1dfc873364cd17d4aca/jetkit/db/__init__.py#L10
faker: FakerFactory = FakerFactory.create()
class SQLAFactory(factory.alchemy.SQLAlchemyModelFactory):
"""Use a scoped session when creating factory models."""
class Meta:
abstract = True
# by providing access to our current sqlalchemy session the factory can automatically
# add newly-created objects to the session (i.e. insert into the DB)
sqlalchemy_session = Session
class UserFactoryFactory(SQLAFactory):
"""Base class for user factories with common fields."""
class Meta:
abstract = True
dob = factory.LazyAttribute(lambda x: faker.simple_profile()["birthdate"])
name = factory.LazyAttribute(lambda x: faker.name())
password = 'my-default-pw!'
avatar_url = factory.LazyAttribute(
lambda x: f"https://placem.at/people?w=200&txt=0&random={random.randint(1, 100000)}"
)
class NormalUserFactory(UserFactoryFactory):
"""Create a user with type=Normal."""
class Meta:
model = NormalUser
email = factory.Sequence(lambda n: f"normaluser.{n}@example.com")
This sets us up with a factory that can produce NormalUser objects. In our setup we use SQLAlchemy polymorphism to distinguish between different user types with different model classes and the UserFactoryFactory (how very enterprise) gives us a base class to quickly define factories for each type of user model.
myapp/test/conftest.py – place to add fixtures made available to your tests. Documentation on these fixtures is provided here.
from myapp.db.fixtures import NormalUserFactory
from pytest_factoryboy import register
register(NormalUserFactory)
This register helper function takes our factory and creates two pytest fixtures out of it. One fixture will be called normal_user which will always return a user object in our DB session, created on demand once per test. The other fixture will be normal_user_factory which will accept arguments to override the factory defaults.
Next we set up fixtures for database, app, and our DB session:
@pytest.fixture(scope="session")
def database(request):
"""Create a Postgres database for the tests, and drop it when the tests are done."""
with DatabaseJanitor(DB_USER, DB_HOST, DB_PORT, DB_NAME, DB_VERSION):
yield
This provides a new database for the entire test session – it’s only created once and dropped when everything is finished.
@pytest.fixture(scope="session")
def app(database):
"""Create a Flask app context for tests."""
# here we pass in config overrides to our create_app
app = create_app(config=dict(SQLALCHEMY_DATABASE_URI=DB_CONN, TESTING=True))
with app.app_context():
yield app
The above code provides us with a Flask app and context for the duration of the entire test session. You can push a new context for each test if you like (remove the scope fixture argument) but I’ve never needed to do this.
@pytest.fixture(scope="session")
def _db(app):
"""Provide the transactional fixtures with access to the database via a Flask-SQLAlchemy database connection."""
from myapp.db import db
db.create_all()
return db
This is the magic hook to provide our database session to pytest-flask-sqlalchemy. We need to provide the package of our SQLAlchemy instance to our pytest configuration in tox.ini:
[pytest]
# mock sqlalchemy database session during testing
mocked-sessions = myapp.db.db.session
Now we can define a fixture for a HTTP client to talk to our app:
@pytest.fixture
def client(app, normal_user):
# get flask test client
client = app.test_client()
access_token = create_access_token(identity=normal_user)
# set environ http header to authenticate user
client.environ_base["HTTP_AUTHORIZATION"] = f"Bearer {access_token}"
return client
This fixture has a dependency on two other fixtures; app and normal_user. We defined the app fixture just above, and the normal_user fixture is automatically added for us by the pytest_factoryboy register helper.
So now that we have a client fixture and a normal_user fixture, we can write very straightforward tests for API calls. Suppose we want to test a user API:
def test_user_api(client, normal_user):
response = client.get("/api/user/0")
assert response.status_code == 404
user_response = client.get(f"/api/user/{normal_user.id}")
assert user_response.status_code == 200
assert user_response.json.get("id") == normal_user.id
The simplicity and compactness of this test is striking. We don’t have any test cases, we define our dependencies in the function arguments, we use straightforward assert statements to check our responses. The test runs in an isolated subtransaction, dependency injection is performed to load the complete dependencies for this particular test, and it couldn’t possibly be any cleaner.
If you’re curious why we’re doing a simple assert here and not something like self.assertEqual() the answer is that pytest overrides the built in assert function with a more test-friendly and powerful version. You will still receive output exactly as you would expect from any test framework if the assertion fails. See the pytest documentation for more details.
Virtual Environments ﹠ Dependencies
The most modern tool for managing dependencies and virtual environments is Pipenv. It’s a bit more npm-style than venv or virtualenvwrapper, with a lockfile, split dev dependencies, and environment management via command line instead of sourcing anything in your shell. It saves the virtual environment files away out of tree.
The downsides for Pipenv are that it is frankly super slow and there hasn’t been an official release in over a year despite very active development. I hope that a faster new release will come out sometime soon.
Pipfiles are the future, no reason to be using requirements.txt anymore.
One more feature that may be of interest to some is the ability to define multiple sources in a Pipfile. If you have certain dependencies that need to be pulled from an internal package index server for example, you can define that source for only those dependencies instead of having to globally change your pypi mirror.
Web Framework
Some of the popular modern web frameworks are Django, Flask, and Falcon.
Django
Django is a pretty heavy solution but has the benefit of everything being set up for you. It’s not a tool I reach for because I normally only try to create lightweight API servers, with little to no server-side rendering of HTML, and I don’t find Django as suited to a serverless architecture as something more lightweight.
Flask
Flask has been our go-to tool for years. It gives you a basic core into which you can plug in components and features as needed. The setup involved in creating the perfect enterprise-ready Flask app from scratch is considerable and takes some experience to get right on your own. The flexibility and ability to craft an application perfectly suited to your needs is invaluable for serious projects, and the simplicity and whipupitude makes it perfect for dead-simple services too.
I’ve written at length about writing serverless web applications with Flask:
- https://spiegelmock.com/2018/11/21/rapid-api-serverless-development/
- https://spiegelmock.com/2018/09/06/serverless-python-web-applications-with-aws-lambda-and-flask/
Falcon
If Flask is too heavy for you, there’s the Falcon microframework. If you’re writing a web service for a system with 64k of RAM and it’s not talking to any database or external services and the CPU overhead of handling HTTP requests and responses is the main bottleneck, Falcon may be a good choice. Their documentation really emphasizes how fast it is. I don’t think your web framework is usually the primary concern when it comes to speed but doubtless there are situations where this is needed.
Digression: Request Globals
<Digression>
There is one funky aspect of how Flask provides access to the current “app” context and the current request context that bothers or confuses some people. There exists an instance of your web application that contains configuration, routes, error handlers, and extensions that comprise your app. When your app is started up a new “app context” is pushed onto the app context stack to keep track of what app is currently active:
from myapp import app
with app.app_context():
do_stuff_with_my_app()
In any code running inside of this context, you can access the current application.
from flask import current_app
def do_stuff_with_my_app():
print(current_app.config['SOME_KEY'])
What’s important here is that current_app is a context variable proxy, which you can treat like a global variable but actually belongs to a context stack and is thread safe. Typically you only need to deal directly with pushing an app context if you’re writing scripts or wrappers that utilize your Flask app instance.
A similar approach is used for the current request context. When your Flask app is running (inside an app context) and a new request comes in, a new request context is pushed onto the request context stack to keep track of the request and request-local variables.
So whereas in many web frameworks like node’s Express you get passed in request and response objects as part of your handler:
app.post('/', function(request, response) {
console.log(request.body);
response.send(request.body);
})
Or in python’s Falcon:
import json
import falcon
class Resource(object):
def on_post(self, req, resp):
body = json.load(req.stream)
print(body)
resp.body = body
resp.status = falcon.HTTP_200
In Flask one might write:
from flask import request
@app.route("/", methods=["POST"])
def app_index():
body = request.get_json()
print(body)
return body
Again, request looks somewhat like a global variable but in reality it is a proxy object to a thread-local object on a context stack. The request is pushed automatically for you by Flask when the request comes in, so you mostly don’t have to know or care about manipulating this stack, unless you are writing some of the more exotic kinds of test cases.
This global-seeming access to context may feel dirty to some, likely conditioned by a healthy aversion to global variables or “god-objects” because of thread safety issues, poor code organization, and the inability to grapple with multiple instances of such objects simultaneously in the same program. These are valid concerns that the LocalProxy objects and context stacks effectively mitigate, while still providing a simple and convenient method to access the instances as needed from anywhere in your codebase, with the only caveat that you are responsible for pushing an app context if you are doing something outside the normal request flow.
I confess that the appeal of this approach was not obvious to me until I tried building a Flask app that talked to a database without using the Flask-SQLAlchemy extension. This extension integrates SQLAlchemy (an ORM) sessions with the Flask contexts so you can always easily access a database session that is local to the current request and transaction, or linked to your app context if not inside a request.
The real value of these context variables comes when you try to modularize your code and database routines. One problem that this solves is when you have a database transaction started inside a request, and then you call into some other code which may call other code which performs queries that should be inside the same transaction, as in a typical atomic operation that a RESTful endpoint might do. Somewhere you must retain a database handle to this operation, and expecting it to be passed through every function that might conceivably call another function that might perform a query is not feasible or clean. Being able to simply import a database session object that is automatically scoped to the finest level of application work you are performing (i.e. to the current request, or not) and assume it belongs to the current database transaction is a truly simple and elegant solution.
This approach has been recognized as a useful tool and in fact in python 3.7 gained first-class support in the form of contextvars from PEP 567. Opinions certainly may differ on the purity and magical-ness of this mechanism but I consider the simplicity and accessibility it affords to be the stronger argument. And given that it is now enshrined in python core means it is unlikely to go away anytime soon.
</Digression>
Putting Into Practice
If some of these ideas sound just splendid to you and you want to try them out, by all means give them a spin. If you’re looking to incrementally adopt new tools and features to your codebase implementing each of these suggestions independently should be manageable. However if you’re starting a new project or want to maximally embrace JetBridge style, it’s a daunting task to configure and wire up all of these practices into a well-organized and clean template. Honestly, setting up the database tests and Flask extensions is tedious. I’m lazy and don’t feel like doing it for new projects. That’s why we’ve created an open-source app starter kit and utility library for rapidly building modern, enterprise-ready python web applications with all of these practices and many more baked in and ready to go. Sort of a Create-React-App (we have one of those too) for our very opinionated python web service setup where we can put these recommendations into practice and save ourselves time setting up each new service.
sls-flask
Our starter kit is called sls-flask. It generates a Flask app skeleton with pytest fixtures, RESTful APIs and serialization, database factories, linting, authentication and more in a serverless-first package. It utilizes our handy JetKit-Flask python library that provides common database utilities (soft delete, upsert, UUIDs), S3 asset support, starting points for authentication and user access and other bits of functionality we’ve found useful in many projects.